
 Twitter
Twitter GitHub
GitHub
Minimizing LLM latency in code generation2 min read
Reading Time: 2 minutesOptimizing Frontier’s Code Generation for Speed and Quality
Introduction
Creating Frontier, our generative front-end coding assistant, posed a significant challenge. Developers demand both fast response times and high-quality code from AI code generators. This dual requirement necessitates using the “smartest” language models (LLMs), which are often slower. While GPT-4 turbo is faster than GPT-4, it doesn’t meet our specific needs for generating TypeScript and JavaScript code snippets.
Challenges
-
Balancing Speed and Intelligence:
- Developers expect rapid responses, but achieving high-quality code requires more advanced LLMs, typically slower in processing.
-
Code Isolation and Assembly:
- We need to generate numerous code snippets while keeping them isolated. This helps us identify each snippet’s purpose and manage their imports and integration.
-
Browser Limitations:
- Operating from a browser environment introduces challenges in parallelizing network requests, as Chromium browsers restrict the number of concurrent fetches.
Solutions
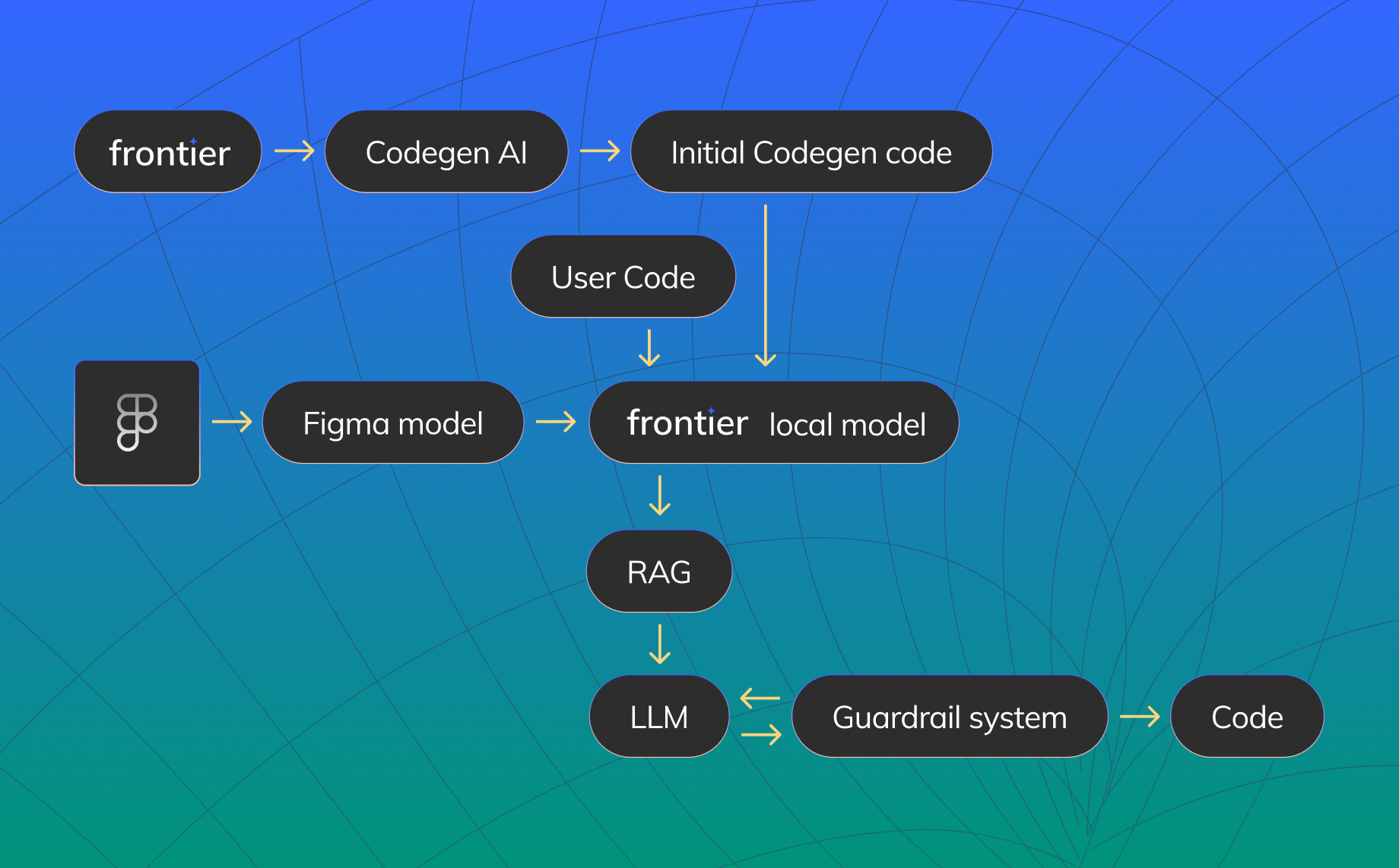
To address these challenges, we implemented a batching system and optimized LLM latency. Here’s how:
Batching System
-
Request Collection:
- We gather as many snippet requests as possible and batch them together.
-
Microservice Architecture:
- These batches are sent to a microservice that authenticates and isolates the front-end code from the LLM, ensuring secure and efficient processing.
-
Parallel Request Handling:
- The microservice disassembles the batch into individual requests, processes them through our regular Retrieval-Augmented Generation (RAG), multi-shot, and prompt template mechanisms, and issues them in parallel to the LLM.
-
Validation and Retries:
- Each response is analyzed and validated via a guardrail system. If a response is invalid or absent, the LLM is prompted again. Unsuccessful requests are retried, and valid snippets are eventually batched and returned to the front end.
Micro-Caching
We implemented micro-caching to enhance efficiency further. By hashing each request and storing responses, we can quickly reference and reuse previously generated snippets or batches. This reduces the load on the LLM and speeds up response times.
Conclusion
The impact of parallelization and micro-caching is substantial, allowing us to use a more intelligent LLM without sacrificing performance. Despite slower individual response times, the combination of smart batching and caching compensates for this, delivering high-quality, rapid code generation.

 in TLV.
in TLV. 